{kind=link}
ในการวัดประสิทธิภาพของ model ที่เราได้สร้างมาด้วยความยากลำบากนั้น ซึ่งเรียกขั้นตอนนี้ว่า evaluate model โดยเราจะแบ่งเป็น 2 กรณี คือ แบบ regression และแบบ classification
1. การวัดประสิทธิภาพโมเดลแบบ regression
ในกรณีที่เป็นแบบ regression หรือ target ข้อมูลเป็นแบบ scale หรือแบบตัวเลขซึ่งมีทั้งแบบ discrete พวกจำนวนเต็มและ continuous แบบต่อเนื่อง เราจะพิจารณาจากค่า error โดยใช้ข้อมูลด้านล่าง ดังนี้
– Mean Squared Error(MSE)
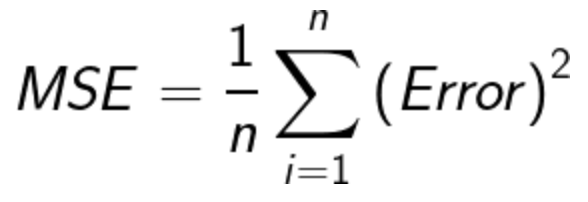
– Root-Mean-Squared-Error(RMSE)
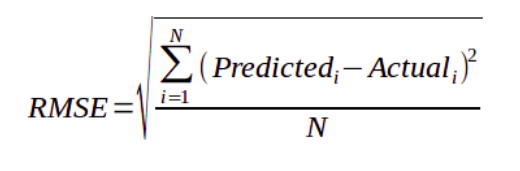
– Mean-Absolute-Error(MAE)
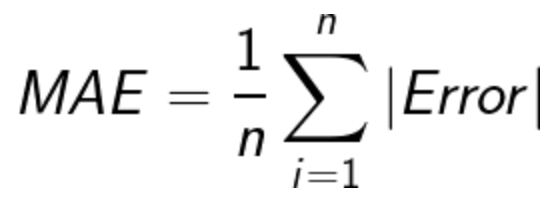
การเลือกใช้งานอาจจะลองใช้ทุกแบบแล้วเทียบกัน หรือพิจารณาจากข้อมูล หากมี outliers ก็อาจจะเลี่ยงการใช้สมการยกกำลังสองไปใช้ตัวอื่นแทนครับ
2. การวัดประสิทธิภาพโมเดลแบบ classification
classification หรือ target เป็นแบบ categorical หรือถ้ามีสองค่าก็จะเรียกว่าไบนารี เช่น การทายว่าเป็นหมาหรือแมว , เป็นมะเร็งหรือไม่เป็น, ท้องหรือไม่ท้อง เป็นต้น กรณีนี้เราจะใช้ดังนี้
◦ Confusion Matrix
◦ Precision and Recall
◦ Accuracy
◦ F-Measure
◦ ROC Graph and Area Under Curve (AUC)
ก่อนอื่นการที่เราจะหาค่า accuracy หรือการวัดผลอื่นๆตามหัวข้อข้างต้น เราต้องมาทำความรู้จักกับ False Positive,True Positive, False Negative,True Negative ซึ่งค่าเหล่านี้เราจะเอาไปแทนในสูตรเพื่อหาค่าวัดผลต่างๆได้ โดยจะได้มาจากตาราง confusion matrix ครับ เรามาดูตัวอย่างกันครับ
Confusion Matrix
confusion matrix ที่เราสามารถพบเจอจะมีรูปแบบ 2 แบบ แบบที่ค่า predict อยู่ซ้ายมือ,actual อยู่ด้านบน กับอีกแบบคือ actual อยู่ซ้ายมือและ predict อยู่ด้านบน จริงๆมันคือตารางเดียวกันแค่สลับตำแหน่ง อยากแยกมาให้ดูไว้ เพราะหลายๆตัวอย่างใช้คนล่ะแบบครับ ตามภาพด้านล่างนี้ครับ
- แบบ predict-actual
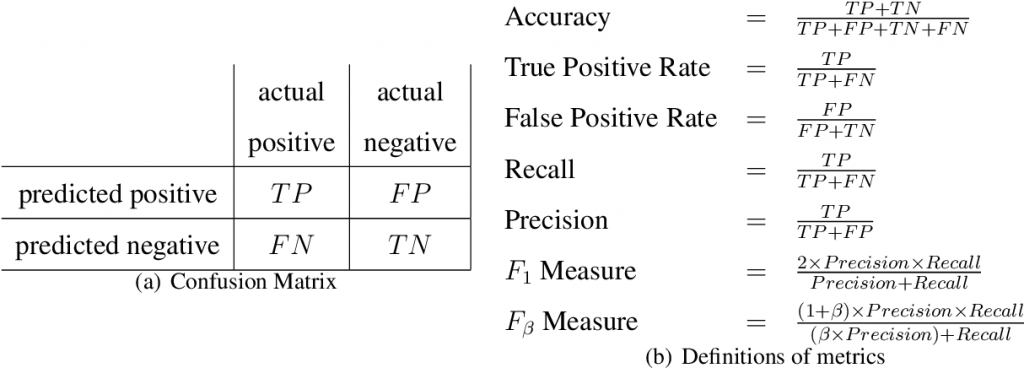
2. แบบ actual-predict
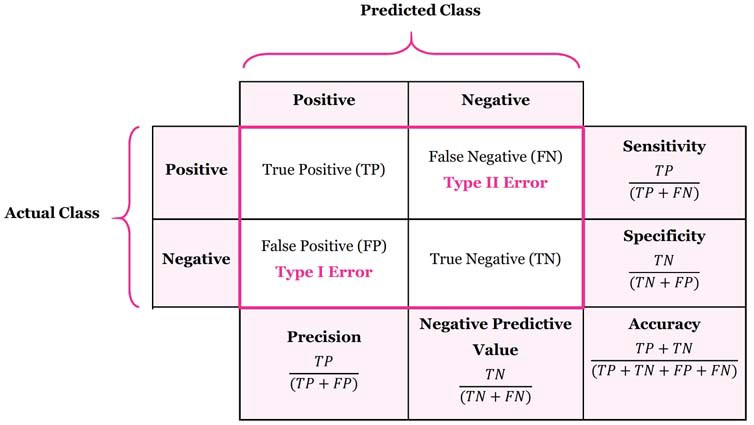
ตัวอย่าง Confusion Matrix

จากภาพข้างบน เป็น confusion matrix แบบ predict-actual ซึ่งในกรณีนี้ผู้ทำภาพซึ่งน่าจะเป็นชาวต่างชาติต้องการสื่อให้เข้าใจง่ายขึ้นครับ ในภาพนี้เราจะแทนคุณหมอให้เป็น model ที่ทำนายว่าคนไข้กำลังตั้งท้องอยู่หรือไม่
1) True Positive คือ ข้อมูลที่ทำนายตรงกับข้อมูลจริงในคลาสที่กำลังพิจารณา (โมเดลบอกท้อง ผลจริงคือท้อง)
2) False Positive คือ ข้อมูลที่ทำนายผิดเป็นคลาสที่กำลังพิจารณา (โมเดลบอกท้อง ผลจริงคือไม่ท้อง)
3) False Negative คือ ข้อมูลที่ทำนายผิดเป็นคลาสที่ไม่ได้พิจารณา (โมเดลบอกไม่ท้อง ผลจริงคือท้อง)
4)True Negative คือ ข้อมูลที่ทำนายตรงกับข้อมูลจริงในคลาสที่ไม่ได้พิจารณา (โมเดลบอกไม่ท้อง ผลจริงคือไม่ท้อง)
จากตัวอย่างนี้ แสดงให้เห็นว่า จะมีกรณีที่เราจำเป็นต้องพิจารณาจากสถานการณ์จริงว่าเหตุการณ์ไหนที่อยู่ในเกณฑ์ที่รับได้หรือเหตุการณ์ไหนที่ต้องระมัดระวังไม่ให้เกิดขึ้น กรณีข้างบนนี้ type 2 error น่าจะไม่ควรให้เกิด เพราะจะทำให้เกิดอันตรายได้ ดังนั้น ควรลดค่า False Negative ให้ได้มากที่สุด ต่อไปเรามาดูว่าจะนำค่าเหล่านี้ไปใช้กับอะไรบ้าง
การคำนวณหาค่าการวัดผลต่างๆ
1) Accuracy
ค่าความถูกต้อง คำนวนได้จากสูตร
Accuracy = (TP+TN)/(TP+TN+FP+FN)
หรือ ค่าที่โมเดลทายถูกทั้งหมด/ค่าทั้งหมด
2) Precision หรือ Positive Predictive Value
ค่าความแม่นยำ
Precision = TP/(TP+FP)
หรือ ค่าที่โมเดลทายเป็นคลาสที่กำลังพิจารณาถูก/ค่าที่โมเดลทำนายว่าเป็นคลาสที่กำลังพิจารณาทั้งถูกและผิด
3) Sensitivity หรือ Recall
ความไว หาค่าได้จากสูตร
Sensitivity/Recall = TP/(TP+FN)
หรือ ค่าที่โมเดลทายเป็นคลาสที่กำลังพิจารณาถูก/ค่าเหตุการณ์จริงเป็นคลาสที่กำลังพิจารณาทั้งถูกและผิด
4) Specificity
ความจำเพาะ หาค่าได้จากสูตร
Specificity = TN/(TN+FP)
5) F1-Score
เป็นค่าที่ได้จากการเอาค่า precision และ recall มาคำนวณรวมกัน (F1 สร้างขึ้นมาเพื่อเป็น single metric ที่วัดความสามารถของโมเดล ไม่ต้องเลือกระหว่าง precision, recall เพราะเฉลี่ยให้แล้ว)
F1 = 2*[(precision*recall)/(precision+recall)]
ROC Curve (receiver operating characteristic)
ในการศึกษาเรื่อง ROC curve มี 2 ประเด็นสำคัญ ที่ต้องให้ความสำคัญ ได้แก่
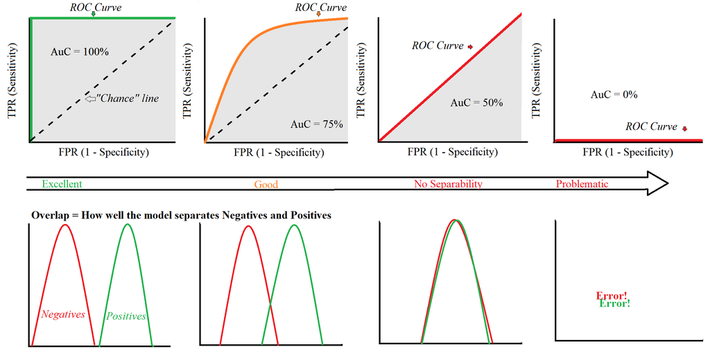
1. Optimal cut-off point ของ ROC
การเลือก Optimal cut-off point หรือจุดที่อยู่บนกราฟ ที่จะได้ค่า AUC มากที่สุด (ให้ผลดีที่สุด) คือ จุดที่อยุ่ใกล้มุมซ้ายบนมากที่สุด ซึ่งจะเป็นจุดที่ Sensitivity สูงและ Specificity สูงด้วยเช่นกัน
2. พื้นที่ใต้กราฟ (AUC; Area under the curve)
ค่า AUC ยิ่งเข้าใกล้ 1 มากยิ่งดี เพราะโมเดลจะมีประสิทธิภาพ
Precision-Recall Curve
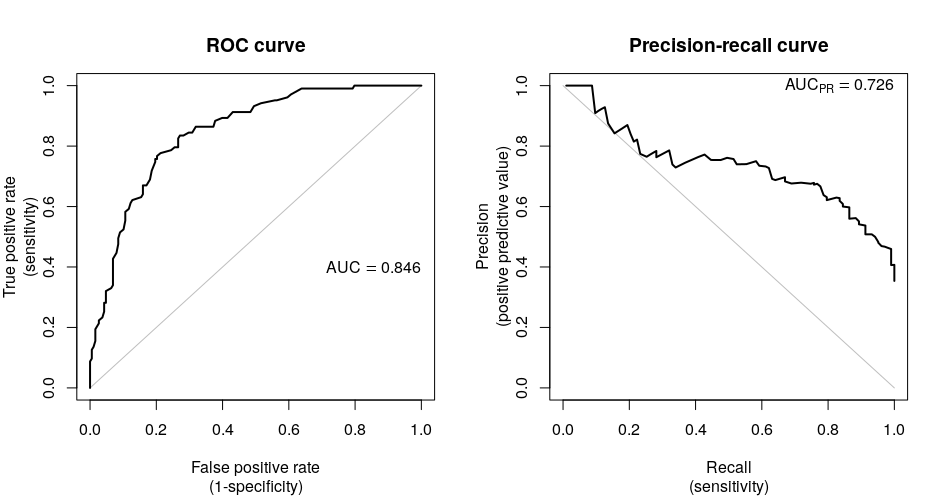
สรุปในส่วนการวัดผล classification คิดว่าคงต้องพิจารณาทั้งหมด ตั้งแต่ confusion matrix จนถึงค่าข้างบนดังกล่าวข้างต้นครับ
27